
Retour d’expérience sur un benchmark simple en environnement réel
Lorsqu’on développe des outils de synchronisation, d’indexation ou de traitement de fichiers (sauvegarde, scan de répertoires, etc.), le parcours récursif du système de fichiers devient très vite un point critique de performance.
Chez DYB, nous avons voulu comparer concrètement deux approches courantes en Python :
os.walk()(méthode historique, très utilisée)os.scandir()(API plus récente et bas niveau)
L’objectif : un benchmark simple, sans optimisation artificielle, exécuté sur des dossiers réels, avec quelques centaines à plusieurs dizaines de milliers de fichiers.
Le benchmark
Le test consiste à :
- parcourir récursivement un dossier
- compter le nombre total de fichiers
- mesurer le temps d’exécution
Même logique, même machine, même code métier.
La seule différence : la méthode de parcours.
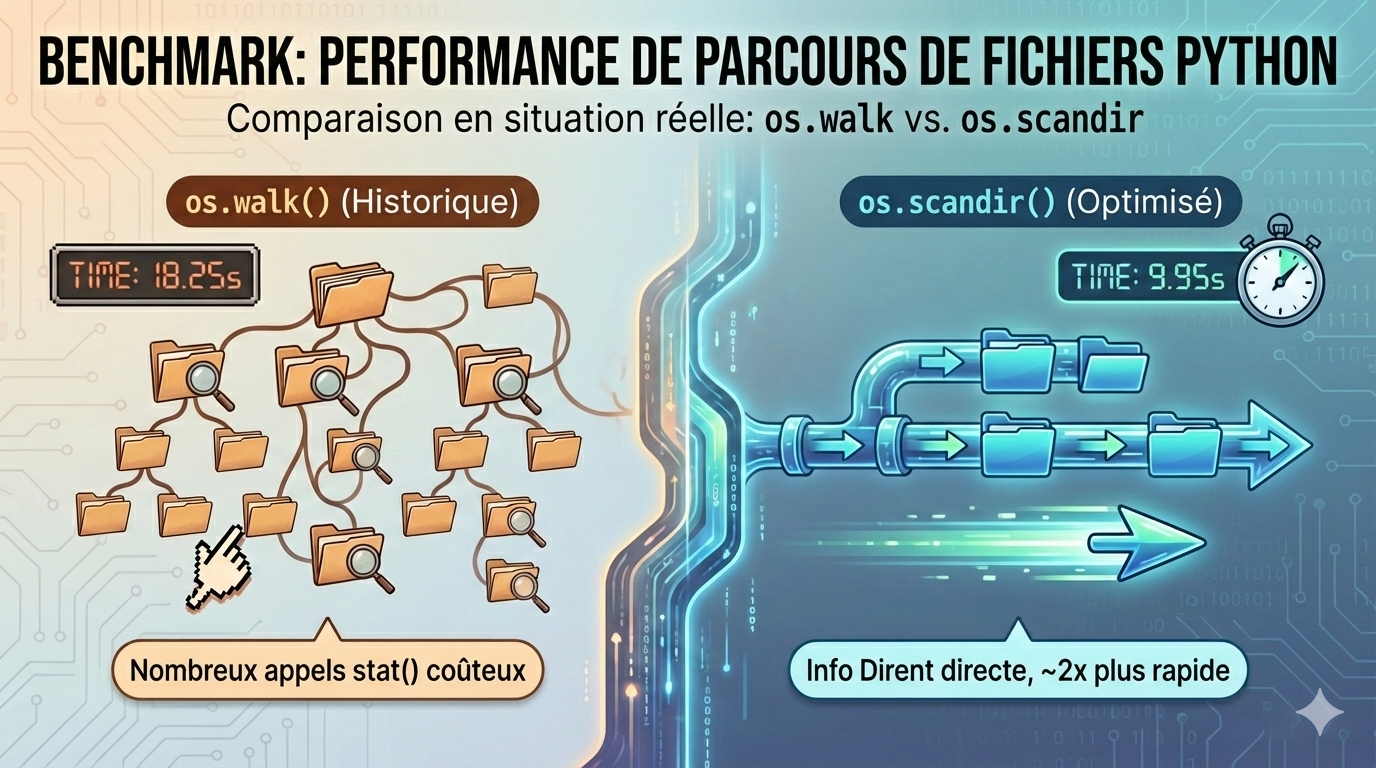
Résultats observés
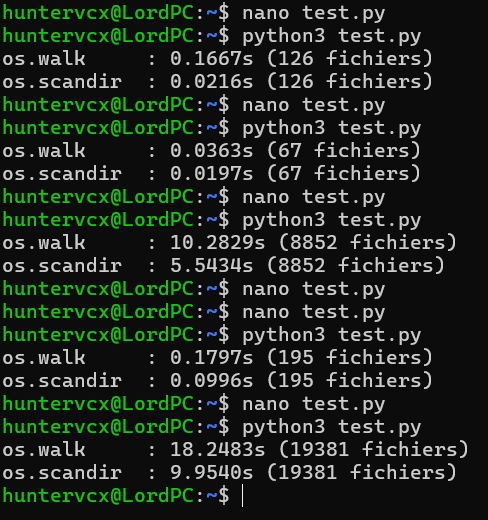
Voici quelques extraits représentatifs des tests réalisés :
| Nombre de fichiers | os.walk() | os.scandir() |
|---|---|---|
| 67 fichiers | 0,036 s | 0,019 s |
| 195 fichiers | 0,180 s | 0,100 s |
| 8 852 fichiers | 10,28 s | 5,54 s |
| 19 381 fichiers | 18,25 s | 9,95 s |
👉 Dans tous les cas, os.scandir() est environ 2× plus rapide.
Et plus l’arborescence est grande, plus l’écart devient significatif.
Pourquoi cette différence ?
1. Le coût caché des stat()
os.walk() repose sur une abstraction plus haut niveau.
Lorsqu’il parcourt les fichiers, Python effectue beaucoup d’appels système stat() pour déterminer si une entrée est un fichier ou un dossier.
Ces appels sont :
- coûteux sur disque
- encore plus lents sur des partages réseau (SMB, NFS, NAS)
- multipliés par le nombre total d’entrées
2. os.scandir() travaille plus bas niveau
os.scandir() utilise directement les informations retournées par le système de fichiers (via dirent sous Linux).
Résultat :
- le type (fichier/dossier) est souvent déjà connu
- pas besoin de
stat()systématique - beaucoup moins de passages kernel ↔ userland
C’est précisément ce qui explique le gain massif de performance.
“Mais os.walk() utilise déjà scandir, non ?”
Oui… en interne, depuis Python 3.5.
Mais :
os.walk()reste une API généraliste- elle génère des tuples complets (
root,dirs,files) - elle fait plus de travail que nécessaire dans des cas simples
👉 Quand on veut juste parcourir vite, os.scandir() utilisé directement reste imbattable.
Pourquoi choisir Python, malgré des performances inférieures à certains langages ?
Il est largement admis que Python est, sur le plan strictement technique, plus lent que des langages compilés comme C, C++ ou Rust. Cette réalité ne constitue cependant pas un défaut en soi, mais plutôt un compromis assumé. Le choix d’un langage ne se limite jamais à la seule performance brute : il implique des considérations de budget, de complexité, de maintenabilité et de dette technique sur le long terme.
Python se distingue avant tout par sa simplicité de conception et de lecture. Un code plus clair réduit le temps de développement, facilite les relectures, limite les erreurs et permet une montée en compétence plus rapide des équipes. À budget égal, cela se traduit par plus de fonctionnalités livrées, plus vite, et avec un risque projet nettement inférieur.
Par ailleurs, tous les projets ne nécessitent pas une optimisation maximale dès leur conception. Dans de nombreux cas, la performance n’est pas le facteur limitant principal, ou peut être améliorée ponctuellement, uniquement là où c’est nécessaire. Python permet précisément cette approche progressive : commencer simple, puis optimiser de manière ciblée, sans sur-ingénierie prématurée.
Enfin, la dette technique est souvent sous-estimée lorsqu’on privilégie des technologies plus complexes dès le départ. Des langages très performants mais plus exigeants en expertise peuvent générer des coûts élevés en maintenance, en recrutement et en évolution fonctionnelle. Python, en réduisant cette complexité initiale, offre un équilibre durable entre efficacité, évolutivité et maîtrise des coûts.
Bref, un peu d'amour pour Python 😉
Cas concrets où la différence est critique
Chez DYB, ce genre de gain est loin d’être théorique. Il est déterminant pour :
- 🔄 outils de synchronisation
- 📂 scan de dossiers autonomes avec plusieurs dizaines de milliers de fichiers
- 🧾 pipelines de traitement data
- 🌐 serveurs de fichiers
- 🧠 moteurs d’indexation
Diviser par deux le temps de scan, c’est :
- moins de charge CPU
- moins d’I/O disque
- moins de latence perçue
- et une meilleure scalabilité globale
Recommandation DYB
👉 Pour tout nouveau développement Python impliquant un parcours récursif de fichiers :
- privilégier
os.scandir()avec une récursion explicite - réserver
os.walk()aux scripts simples ou non critiques
Ce choix seul peut transformer un script “acceptable” en un outil réellement industriel.
Si vous travaillez sur des problématiques de performance, stockage, automatisation ou traitement de fichiers à grande échelle, DYB accompagne ses clients de l’architecture jusqu’à l’optimisation bas niveau.
📩 Contactez-nous pour en discuter.



0 commentaire